WHY THIS MATTERS IN BRIEF
Historically AI’s have learned how to caption images, but now they’re learning how to make images from text and it will revolutionise content creation.
 Love the Exponential Future? Join our XPotential Community, enjoy exclusive content, future proof yourself with XPotential University, connect, watch a keynote, or browse my blog.
Love the Exponential Future? Join our XPotential Community, enjoy exclusive content, future proof yourself with XPotential University, connect, watch a keynote, or browse my blog.
Artificial Intelligence (AI) is getting better and better at generating synthetic content, from art, blogs, books, and imagery, to music and videos, from scratch using nothing but data and some new fangled AI imagination. And over the past year or so I’ve shown off AI’s that can generate basic videos from text, generate images from your brainwaves, create realistic human faces from nothing more than mere doodles, and even create photo-real DeepFake news anchors from text.
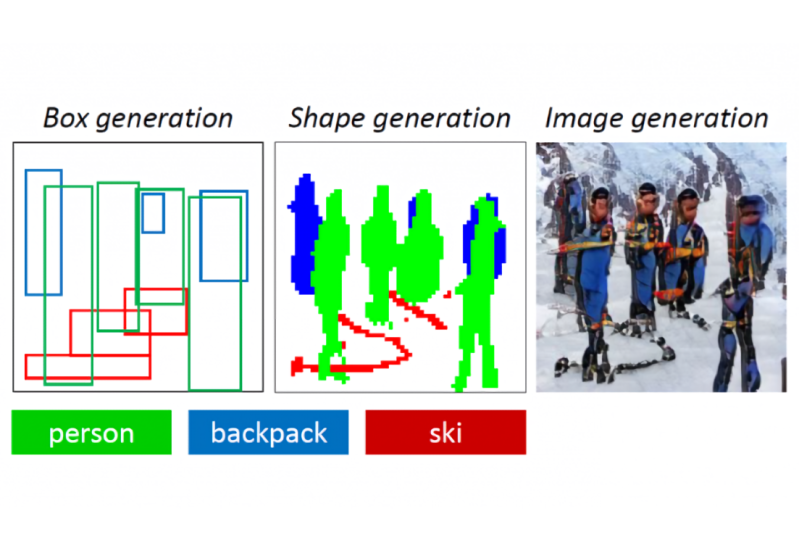
Now Microsoft, the University of Albany, and JD AI Research have unveiled an AI that can sketch images, albeit slightly abstract ones for now, from nothing more than captions, and they published their work, called objGAN, in IEEE. The paper’s co-authors also claim the approach they used to build their new toy resulted in a “significant boost” in picture quality compared with previous state-of-the-art techniques.
“Our [generators] are able to use the fine grained word and object level information [in the captions] to gradually refine their synthetic images,” they wrote. “Extensive experiments then demonstrated objGAN’s effectiveness and ability to generalise imagery using Text-to-Image generation for complex scenes.”
A formidable challenge in developing Text-to-Image AI is imbuing the system with an understanding of object types, the team notes, as well as getting it to comprehend the relationships among multiple objects in a scene. Previous methods used image-caption pairs that provided only coarse-grained signals for individual objects, and even the best-performing models have trouble generating semantically meaningful photos containing more than one object.

Basic today, photorealistic in less than three years time …
To overcome these blockers, the researchers fed ObjGAN – which contains a Generative Adversarial Network (GAN), a two-part neural network consisting of generators that produce samples and discriminators that attempt to distinguish between the generated samples and real-world samples – 100,000 labels (each with segmentation maps and five different captions) from the open source COCO data set. Over time, the AI system internalized the objects’ appearances and learned to synthesize their layouts from co-occurring patterns in the corpus, ultimately toward generating images conditioned on the pre-generated layouts.
In an attempt to achieve human-level performance in image generation, the team modelled in ObjGAN the way artists draw and refine complicated scenes. The system breaks input text into individual words and matches these words to specific objects in the image, and it leverages two discriminators — an object-wise discriminator and patch-wise discriminator — to determine whether the work is realistic and consistent with the sentence description.
As you can see the results aren’t perfect — ObjGAN occasionally spits out logically inconsistent samples, like a train marooned on a grassy knoll for the caption “A passenger train rolling down the tracks” — but they’re nonetheless impressive considering they’re synthesized from scratch – and the technology will improve quickly from here on in as technology does.
Not content with just producing images from captions next the teams, along with Duke University, Tencent AI Research, and Carnegie Mellon University, went about trying to get their AI’s to create comic like storyboards from those captions, and they describe that work in another paper called StoryGAN.












