WHY THIS MATTERS IN BRIEF
As AI’s use becomes ubiquitous, from surveillance to crime fighting, innovations like this are a double edged sword.
 Interested in the Exponential Future? Connect, download a free E-Book, watch a keynote, or browse my blog.
Interested in the Exponential Future? Connect, download a free E-Book, watch a keynote, or browse my blog.
Artificial Intelligence (AI) is now becoming the foundational technology that’s helping create a host of new products and services. In the world of forensics and surveillance those include the ability to use it to build out a range of comprehensive and frighteningly good pre-crime technology stacks, as well as using AI to determine a person’s character and personality from photos, as well as their intent to criminality, identify people even when masked, spot shoplifters before they thieve, and catch liars and even murderers in the act – all with scary levels of accuracy and efficiency. Furthermore, and taking this one step more weird, this tech could also be used to create a photo of your face from your voice print, and that photo could then be turned into a 3D DeepFake video thanks to Samsung’s own most recent AI breakthrough. Nuts eh!? Remember what I always say – think exponential tech combinations not just tech and you have your future right there.
Recently though in an adjacent field police departments managed to create accurate photofits of suspects just from their DNA, but now AI and the team from start up Speech2Face, has taken this latter capability one step further and managed to figure out how to create above average approximate photofits of people just by listening to their voice. Just think about that for a moment… now read on. The researchers published their paper on arXiv.

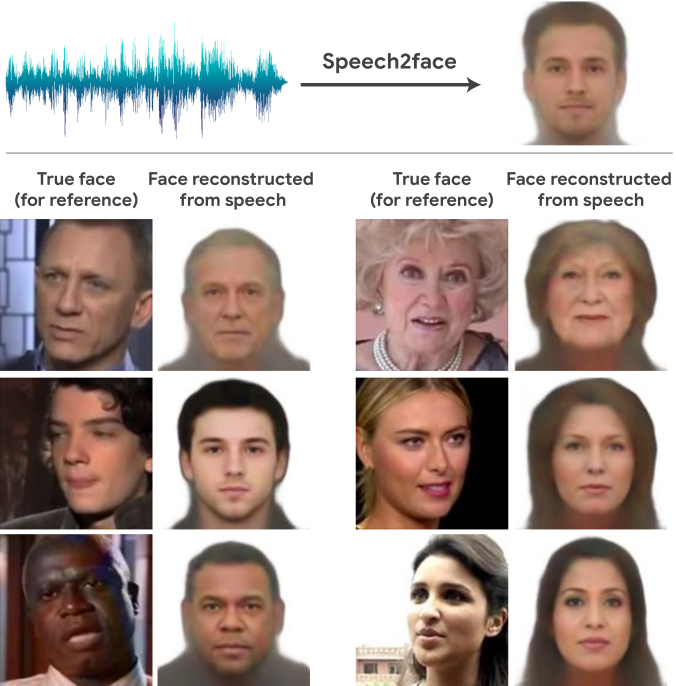
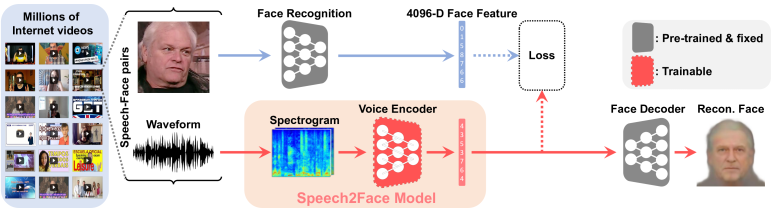
Courtesy: Speech2Face
In order to accomplish its crazy feat the neural network recognized certain markers in speech that pointed to gender, age and ethnicity, features that are shared by many people, the study authors reported – in much the same way that you or I try to imagine what someone might look like when we’re talking with them on the phone.
“As such, the model will only produce average looking faces,” the scientists wrote. “It will not produce images of specific individuals.” So, it’s not that accurate yet, but still it’s a good start and the system will only improve over time.
The faces generated by Speech2Face, all facing front and with neutral expressions, didn’t precisely match the people behind the voices but the images did usually capture the correct age ranges, ethnicities and genders of the individuals, according to the study.
However, the algorithm’s interpretations were far from perfect. Speech2Face demonstrated “mixed performance” when confronted with language variations. For example, when the AI listened to an audio clip of an Asian man speaking Chinese, the program produced an image of an Asian face. However, when the same man spoke in English in a different audio clip, the AI generated the face of a white man, the scientists reported.
The algorithm also unsurprisingly showed gender bias, associating low-pitched voices with male faces and high-pitched voices with female faces. And because the training dataset represents only educational videos from YouTube, it “does not represent equally the entire world population,” the researchers wrote.
Another concern about this video dataset arose when a person who had appeared in a YouTube video was surprised to learn that his likeness had been incorporated into the study, Slate reported. Nick Sullivan, head of cryptography with the internet security company Cloudflare in San Francisco, unexpectedly spotted his face as one of the examples used to train Speech2Face, and which the algorithm had then reproduced just using his voice alone. And the fact that he managed to recognise his own reproduced face should be enough to tell you that there might, just might, be something to this approach so it’ll be an interesting trend to follow so stay tuned.
Source: GeneralAI













